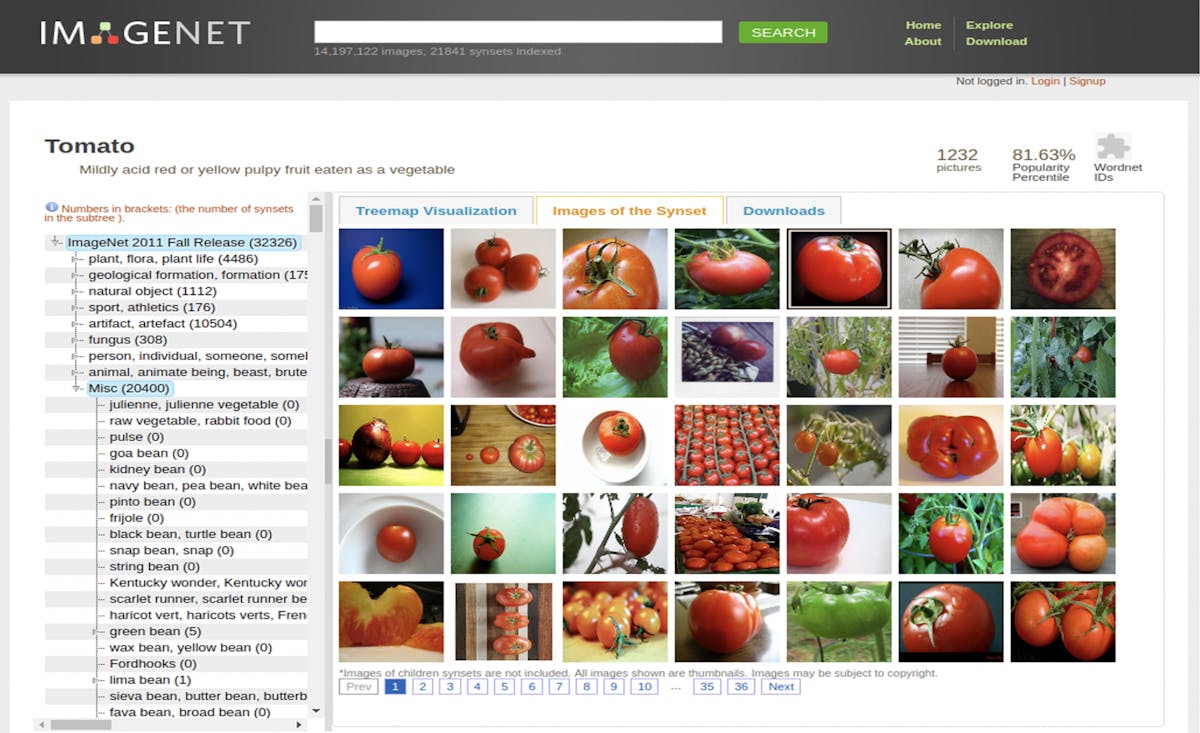
The fusion of image data and metadata, which marks a paradigmatic shift in the recent history of photography, is the reason and foundation for the diverse harvesting and mining technologies based on images that are so pervasive in contemporary computing. Photography, understood in its broader sense as the “historical totality of photographic forms” 1Peter Osborne, “Infinite Exchange: The Social Ontology of the Photographic Image,” Philosophy of Photography, Vol. 1, No. 1 (2010): 59–68, here: 61. that includes, among others, digital photography and scanning technologies, has become indispensable in a wide range of scientific disciplines as well as in manufacturing and industrial agriculture. In robotics, for example, which experiments with computer vision to further automatise and optimise industrial processes, photography operates in several ways. Annotated image databases such as ImageNet (fig. 1), the Open Images database or the many internal datasets of the Big Five (Apple, Amazon, Facebook, Google, Microsoft) gather several millions of indexed photographs. These masses of photographs, organised in more or less homogeneous datasets, are the source material for the development of visual object recognition software. 2See also, Jeff Guess, “Conversations,” in Dossier “Câble, copie, code. Photographie et technologies de l’information,” eds. Estelle Blaschke and Davide Nerini, Transbordeur. Photographie histoire société, No. 3 (2019): 36–47. This software is used in greenhouse farming, for instance. In the example of Root AI, an US American AI farming startup company recently acquired by AppHarvest, the software is programmed to detect and analyse tomato sizes within particular bounding boxes (fig. 2). If the software determines that the tomatoes are ripe, they are picked by a camera-equipped robot (fig. 3). The ultimate goal is a machine-to-machine communication that largely operates without human direction. In addition, photographs are continuously created to monitor every aspect of the production process. While these technologies are still far from being a scalable practice – human labour, after all, especially in agriculture, is still more accurate, flexible and cheaper – they represent an additional function of contemporary photography: Photography as a catalyst for machine learning.
Fig. 2 and 3: Root AI, Screenshots from promotional clip, 2018
With the exponential increase in image production, more and more image data and metadata, either embedded or added to an image, is being collected and stored. As outlined in the previous post, metadata is essential for organising, visualising and retrieving images that circulate online. From administrative and descriptive metadata to the likes and hashtags, metadata affect how, when and where an image appears in the digital environment. At the same time they are extraordinarily fluid and unstable. When images are copied and shared, metadata can easily be scrapped or modified.
From the perspective of the copyright holder and by extension the picture industry, this is seen as extremely problematic. Metadata is critical to this business as it contains the proof of ownership that is crucial to licensing. So, what happens when images travel what they do so well in digital form? A 2015 survey conducted by the International Press Telecommunication Council (IPTC) showed that only fragments of embedded technical or qualitative metadata are displayed when images are uploaded to social media sites. Copyright information, in particular, is handled casually and the culture of free open access to content that permeates the web has contributed significantly to the crisis of the picture industry. To counter the effects of the potential loss of metadata, the picture industry has pushed for reverse image search mechanisms that allow images to be traced, or the development of blockchain technology for image management. Blockchain technology promises a decentralised, immutable ledger that records the provenance and “history” of a digital asset (fig. 4). All data, all transactions are encapsulated and sealed in the log and would allow the rights holder to control usage. In addition, the IPTC along with several other associations, has been a strong advocate for the Digital Single Market Copyright Directive, which was approved by EU countries in 2019. The aim of the directive is to ensure the liability of online platforms for uploaded content and the accompanying remuneration of authors and rights holders.
However, from the perspective of social media sites, the malleability of metadata has largely paid off (so far): As mentioned above, in most cases metadata is not displayed when an image is uploaded to a social media site. But that does not mean that they are not used by the platform provider in question. Image-centric social media sites may have little interest in looking at the images collected on their sites, except for training image-recognition algorithms. However, they do have a vested interest in monetising the data they collect.
Image data and metadata have become a new commodity in data capitalism or surveillance capitalism, a term coined by Shoshana Zuboff. 3Shoshana Zuboff, The Age of Surveillance Capitalism. The Fight for a Human Future at the New Frontier of Power (New York, 2019). Metadata, in general, is exploited for a variety of purposes: to influence search results, to customise advertising, to contribute to scientific research, and as a tool for surveillance. 4Sarah Myers West, “Data Capitalism: Redefining the Logics of Surveillance and Privacy,” Business and Society, Vol 58 (I), 2019: 20–41. According to Zuboff, at the heart of all these mining practices is the behavioural data gathered when interacting with online services. Photographs, it could be argued, provide a particular form of behavioural data. On the one hand, behavioural data are collected when a photograph is taken that captures the human experience (fig. 5). On the other hand, they are collected when we search for images, when an image is uploaded to a platform or when users interact with the image in the form of likes and comments as part of their everyday experience. Tech companies, whose business models are based on data collection, such as Google, consider these captured experiences and interactions with images as free “raw” material that can be turned into products. As Zuboff goes on to point out, behavioural data is computed and then packaged as prediction products that help commercial clients anticipate what their potential customers might do or want. It is an inherent part of the success of these practices that they remain largely opaque, and as Zuboff explains with respect to Google’s original business model these “methods had to be undetectable … so that we [users] could not contest.” 5Zuboff, The Age of Surveillance Capitalism, 14–16. Taken together, these practices mark the increasing shift in value towards image data and metadata.
The utilitarian uses of photography, some of which have been outlined in this blog, remain an understudied field in the history of analogue and digital photography. The extent of these uses in contemporary practices where aesthetics play a subordinate role may lead to a renewed interest in the long history of utilitarian practices that have conditioned the environments in which we live.
From Zurich to Winterthur: S 12, IC Zurich-St. Gallen and IR Zurich-Schaffhausen (20–25 min).
From Zurich Airport: IC and IR trains (15 min).
From St. Gallen: IC and IR trains (40–45 min).
From Schaffhausen: IC and IR trains (35 min).
Bus
From Winterthur train station: Bus no. 2 (direction Seen), 3 stops till “Fotozentrum”.
Car
Motorway from Zurich: exit Winterthur-Töss, direction “Zentrum” (City Centre), then follow the sign “Fotomuseum”.Motorway from St. Gallen: exit Oberwinterthur, direction “Zentrum” (City Centre), then follow the sign “Fotomuseum”.Parking facilities near the museum.